در این پست قرار است درباره یکی از راهحلهای پایدارتر کردن سیستم صحبت کنیم. امروزه استفاده از سرویسهای خارجی یا همان external services در برنامههای وب بسیار رایج است. برنامههای سمت سرور معمولاً از این سرویسها برای دریافت و ارسال اطلاعات استفاده میکنند. سرویسهایی مانند درگاههای پرداخت، درگاههای ارسال پیامک و ایمیل از جمله رایجترین سرویسهای خارجی مورداستفاده است.
استفاده از همین سرویسهای خارجی باعث میشود که توجه به الگوهای پایداری سیستمهای توزیع شده (distributed systems) اهمیت یابد. زیرا سیستمهای توزیع شده بر بستر شبکه قرار دارند و این بستر شبکه خود دارای مشکلاتی است که برنامهنویسان کمتر به آن توجه میکنند. یکی از استدلالهای غلط قابلاعتماد بودن بستر شبکه (network) است.

the network is not reliable
همین استدلال اشتباه در نقاط حیاتی سیستم مشکلاتی را به وجود میآورد. یکی از این نقاط حیاتی سرویسهای درگاههای پرداخت اینترنتی (ipg) هستند. گاهی پیش میآید که به دلایل مختلف درخواستهای پرداخت با خطای timeout و یا دیگر خطاهای مرتبط با بستر شبکه برخورد میکنند. توجه به این خطاها و استفاده از الگوهایی برای جلوگیری از این معضلات، نقش خیلی مهمی در ارتقای سطح پایداری سیستم (system stability) دارند.
در خیلی از موارد خطاهای بستر شبکه خطاهای گذرا (transient) هستند و در چند لحظه اتفاق افتاده و برطرف میشوند. برای اینکه بتوان سیستم را در مواجهه با این نوع خطاها مقاوم کرد میتوان از الگوی تلاش مجدد retry pattern استفاده کرد.
اگر یک برنامه زمانی که میخواهد درخواستی را به یک سرویس دهنده ارسال کند، نقصی را تشخیص دهد، میتواند با استفاده از استراتژیهای زیر با شکست مواجه شود:
Cancel
اگر خطا نشان میدهد که خرابی گذرا نیست یا در صورت تکرار بعید است موفقیتآمیز باشد، برنامه باید عملیات را لغو کرده و یک exception را گزارش کند. بهعنوانمثال، شکست احراز هویت ناشی از ارائه credentials نامعتبر، مهم نیست که چند بار تلاش شده است.
Retry
اگر خطای خاص گزارش شده غیرعادی یا نادر باشد، ممکن است ناشی از شرایط غیرعادی مانند خرابشدن packet شبکه در حین انتقال باشد. در این حالت، برنامه میتواند بلافاصله درخواست ناموفق را دوباره امتحان کند، زیرا بعید است که همان شکست تکرار شود و احتمالاً درخواست موفقیتآمیز خواهد بود.
Retry after delay
اگر خطا ناشی از یکی از رایجترین اتصالات یا خرابیهای شلوغ باشد، شبکه یا سرویس ممکن است به مدت کوتاهی نیاز داشته باشد تا مشکلات اتصال اصلاح شود یا کارهای عقبافتاده پاک شود. برنامه قبل از امتحان مجدد درخواست باید برای زمان مناسب منتظر بماند.
برای خرابیهای گذرا رایجتر، دوره بین تلاشهای مجدد باید انتخاب شود تا درخواستها از چند نمونه برنامه تاحدامکان به طور یکنواخت پخش شوند. این احتمال بارگیری بیش از حد یک سرویس مشغول را کاهش میدهد. اگر بسیاری از نمونههای یک برنامه به طور مداوم سرویسی را با درخواستهای امتحان مجدد قرق میکنند، بازیابی سرویس بیشتر طول میکشد.
برنامه میتواند منتظر بماند و تلاش دیگری انجام دهد. در صورت لزوم، این فرایند را میتوان با افزایش تأخیر بین تلاشهای مجدد تکرار کرد، تا زمانی که حداکثر تعداد درخواستها انجام شود. بسته به نوع خرابی و احتمال تصحیح آن در این مدت، تأخیر را میتوان بهصورت تدریجی یا تصاعدی افزایش داد.
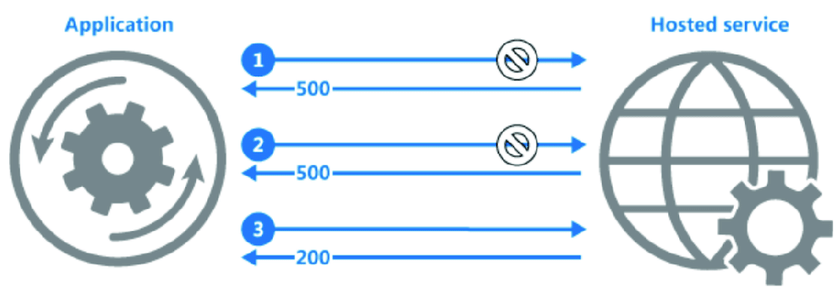
نمودار زیر فراخوانی عملیات در یک سرویس میزبانی شده با استفاده از این الگو را نشان میدهد. اگر درخواست پس از تعدادی تلاش از پیش تعیین شده ناموفق باشد، برنامه باید خطا را بهعنوان یک استثنا تلقی کرده و آن را مطابق با آن رسیدگی کند.

retry pattern
زمان استفاده از این الگو
از این الگو زمانی استفاده کنید که یک برنامه ممکن است هنگام تعامل با یک سرویس دهنده، خطاهای گذرا را تجربه کند. انتظار میرود این خطاها کوتاهمدت باشند و در صورت تکرار ارسال درخواستی که قبلاً شکستخورده است میتواند در تلاش بعدی موفق شود.
این الگو ممکن است مفید نباشد
هنگامی که یک خطا احتمالاً طولانیمدت است، زیرا این میتواند بر پاسخگویی یک برنامه تأثیر بگذارد. برنامه ممکن است در تلاش برای تکرار ریکوئستی که احتمال شکست آن وجود دارد، زمان و منابع را تلف کند.
بهعنوان جایگزینی برای پرداختن به مسائل مقیاسپذیری در یک سیستم. اگر برنامهای با خطاهای busy مکرر مواجه میشود، اغلب نشانه آن است که سرویس یا منبعی که به آن دسترسی دارید باید بزرگتر شود.