
طراحی یک سیستم با قابلیت پشتیبانی از میلیونها کاربر، یک چالش چشمگیر و مسیری طولانی از بهبود و تکامل بیپایان را به دنبال دارد. در این فصل، از یک سیستم ساده و قابل استفاده تنها برای یک کاربر، شروع کرده و آن را به صورت گام به گام گسترش میدهیم تا به سیستمی که قابلیت پشتیبانی از میلیونها کاربر را دارد، دست یابیم. پس از مطالعهی این فصل، شما تعدادی از تکنیکهای کاربردی را که در طراحی سیستم به شما کمک خواهند کرد، به طور کامل مسلط خواهید شد.
راهاندازی با یک سرور
الگوی “راهاندازی با یک سرور”، یک شروع استوار برای طی کردن مسیری پرماجرا در ساختار یک سیستم پیچیده است. برای آغاز کار با چیز سادهتر، همهی عناصر سیستم، شامل برنامه وب، پایگاه داده، حافظه نهان و سایر اجزای آن، روی یک سرور قرار داده میشوند. شکل ۱-۱، نمایی از الگوی “راهاندازی با یک سرور” است که در آن همهی عناصر سیستم، از جمله برنامه وب، پایگاه داده و حافظه نهان، بر روی یک سرور اجرا میگردند.
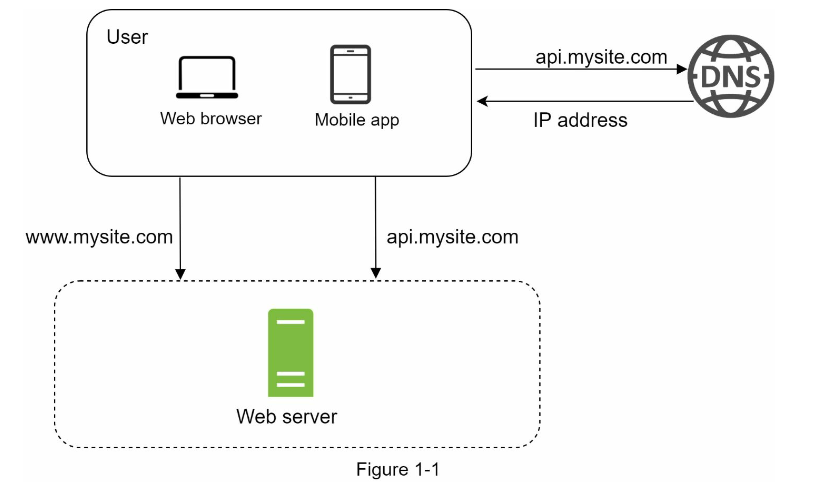
برای درک بهتر این گراف، بهتر است که جریان درخواست و منبع ترافیک را مورد بررسی دقیق قرار دهیم. ابتدا، به جریان درخواست (شکل ۱-۲) نگاهی بیندازیم.
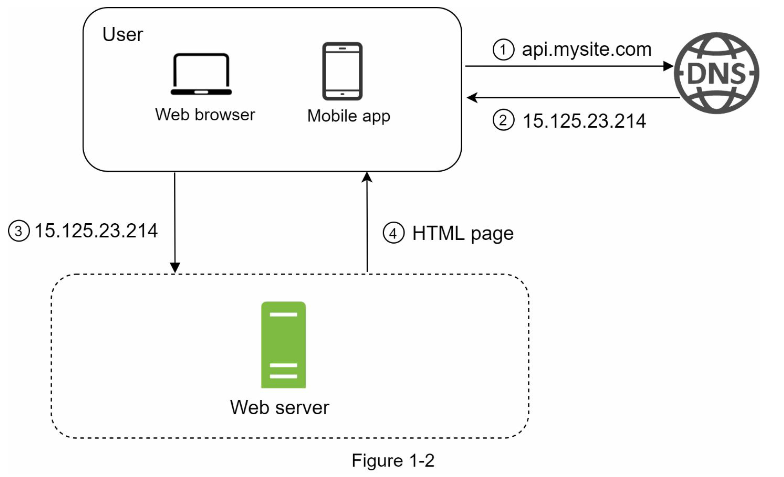
۱. کاربران به وبسایتها از طریق نام دامنهها، مانند api.mysite.com، دسترسی پیدا میکنند.
۲. نشانی پروتکل اینترنت (IP) به مرورگر یا برنامه تلفن همراه بازگردانده میشود. در مثال، آدرس IP 15.125.23.214 بازگشت داده شده است.
۳. پس از دریافت آدرس IP، درخواستهای پروتکل انتقال ابرمتن (HTTP) به صورت مستقیم به سرور وب شما ارسال میشوند.
۴. سرور وب صفحات HTML یا پاسخ JSON را برای پردازش برمیگرداند.
حال به منبع ترافیک بپردازیم. ترافیک به سرور وب شما از دو منبع وب و موبایل در میآید:
• برنامه وب: از زبانهای سمت سرور (Java، Python، و غیره) برای هندلینگ منطق کسب و کار، ذخیره سازی و غیره استفاده میشود، و از زبانهای سمت مشتری (HTML و JavaScript) برای نمایش استفاده میکند.
• برنامه موبایل: پروتکل HTTP برای ارتباط بین برنامه تلفن همراه و سرور وب استفاده میشود. به دلیل سادگی آن، فرمت پاسخ API JSON به عنوان فرمت پاسخ معمولاً مورد استفاده قرار میگیرد.
دیتابیس
با گسترش کاربران، استفاده از یک سرور دیگر کافی نیست و برای پاسخگویی به نیازهای رو به رشد باید از چندین سرور استفاده کرد. به عنوان مثال، برای مدیریت بار کاری به دو نوع سرور نیاز داریم: یک سرور برای مدیریت ترافیک وب و موبایل و دیگری برای مدیریت پایگاه داده (همانطور که در شکل 1-3 نشان داده شده است). با تفکیک این دو نوع سرور به دو لایه (لایه وب و لایه داده)، امکان مقیاس پذیری مستقل از هم فراهم می شود.
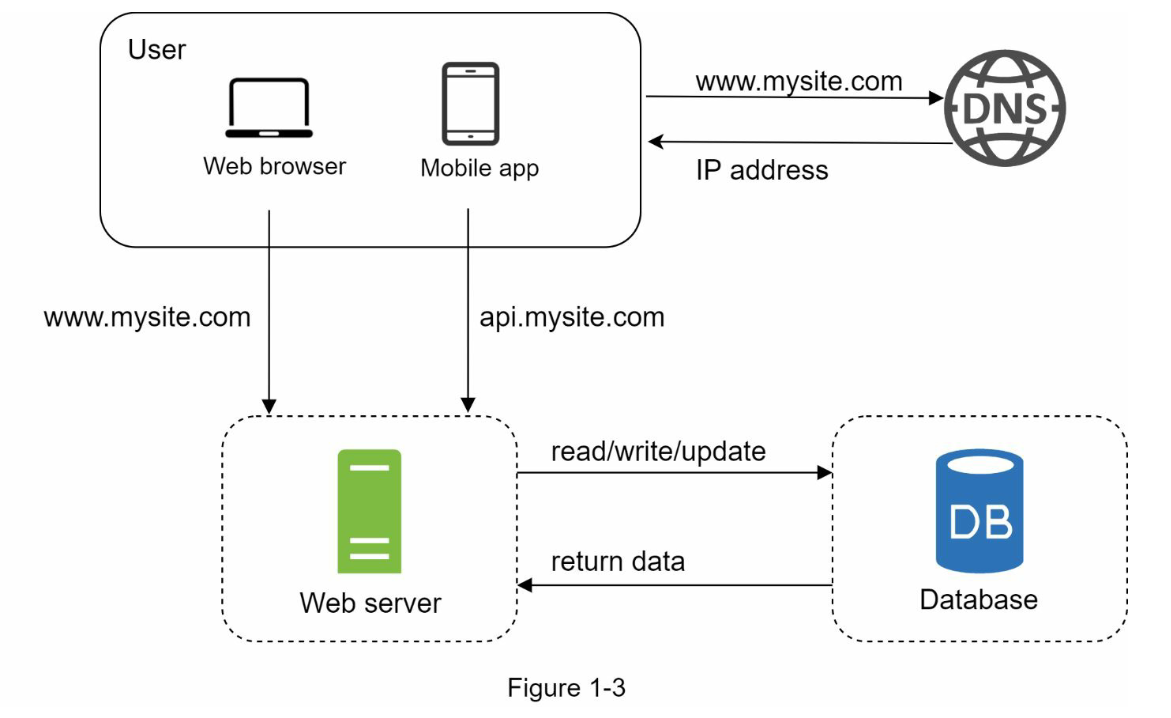
از کدام پایگاه داده استفاده کنیم؟
درباره انتخاب دیتابیسها شما میتوانید بین دیتابیس رابطهای سنتی و دیتابیس غیررابطهای (NoSQL) انتخاب کنید. برای درک تفاوت آنها، بهتر است به بررسی این دو نوع دیتابیس بپردازیم.
دیتابیسهای رابطهای همچنین به دیتابیس مدیریت رابطهای (RDBMS) یا دیتابیس SQL نیز شناخته میشوند. پرطرفدارترین آنها عبارتند از MySQL، پایگاه داده Oracle، PostgreSQL و غیره. دیتابیسهای رابطهای دادهها را در جداول و ردیفها نمایش و ذخیره میکنند. شما میتوانید با استفاده از SQL، عملیات ادغام (join) را بین جداول مختلف پایگاه داده انجام دهید.
دیتابیسهای غیررابطه ای همچنین به دیتابیس NoSQL نیز شناخته میشوند. معروفترین آنها عبارتند از CouchDB، Neo4j، Cassandra، HBase، Amazon DynamoDB و غیره. این دیتابیسها در چهار دسته کلی ذخیره سازی کلید-مقدار، ذخیره سازی گراف، ذخیره سازی ستونی و ذخیره سازی سند تقسیم بندی میشوند. عموماً عملیات joinدر دیتابیسهای نارابطهای پشتیبانی نمیشود
برای اکثر برنامهنویسان، پایگاههای داده رابطهای بهترین گزینه به شمار میآیند. با این حال، اگر پایگاههای داده رابطهای برای مورد کار خاص شما مناسب نیستند، بسیار حیاتی است که خارج از این دسته از پایگاههای داده نیز جستجو کنید. در این موارد، پایگاههای داده غیررابطهای ممکن است گزینه مناسبی باشند، به شرطی که:
- برنامه شما نیاز به حداقل زمان تأخیر دارد.
- دادههای شما بدون ساختار هستند یا شما دارای دادههای رابطهای نیستید.
- تنها نیاز دارید به سریالیزه و دیسریالیزه کردن دادهها (مانند JSON، XML، YAML و غیره).
- نیاز دارید به ذخیره حجم زیادی از دادهها.
مقیاس پذیری عمودی یا افقی مسئله این است
مفهوم اسکیلینگ (Scaling) به دو روش انجام میشود: اسکیلینگ عمودی (Vertical Scaling) یا “اسکیل آپ” که به معنی افزودن تواناییهایی مانند پردازشگر، حافظهی رم و غیره به سرورهای شماست و اسکیلینگ افقی (Horizontal Scaling) یا “اسکیل آوت” که با اضافه کردن سرورهای جدید به منابع شما، میتوانید مقیاس پذیری خود را بالا برده و افزایش قابل توجهی در عملکرد داشته باشید.
اگر ترافیک کم باشد، اسکیلینگ عمودی گزینهی مناسبی است و سادگی آن از مزیتهای اصلی آن است. با این حال، این روش محدودیتهای جدی دارد:
- اسکیلینگ عمودی حد بالایی دارد و امکان افزودن بیشترین تعداد پردازشگر و حافظهی رم به یک سرور وجود ندارد.
- اسکیلینگ عمودی دارای قابلیت Failover و redundancy نیست. در صورتی که یک سرور خراب شود، وبسایت/اپلیکیشن کاملاً متوقف میشود.
از آنجایی که اسکیلینگ عمودی محدودیتهای خود را دارد، اسکیلینگ افقی برای برنامههای بزرگ مقیاس مطلوبتر است.
در طرح قبلی، کاربران به صورت مستقیم به سرور وب متصل میشوند. در صورتی که سرور وب خاموش باشد، کاربران نمیتوانند به وب سایت دسترسی پیدا کنند. در سناریوی دیگر، اگر تعداد زیادی کاربر به صورت همزمان به سرور وب دسترسی داشته باشند و آن سرور به حد لود خود برسد، کاربران به طور عمومی با پاسخ نامناسب یا عدم اتصال به سرور مواجه خواهند شد. load balancer بهترین روش برای حل این مشکلات است.
Load balancer
یک لودبالانسر به طور یکنواخت، ترافیک ورودی را بین سرورهای وبی که در یک مجموعه لودبالانس شده تعریف شدهاند، توزیع میکند. به طور کلی، وظیفه لودبالانسر بر عهده توزیع بارکاری بین سرورهای متصل به آن است تا در نتیجه، کارایی و قابلیت اطمینان سیستم افزایش یابد. لودبالانسر علاوه بر این که میتواند برای افزایش پایداری، سرعت و قابلیت اطمینان شبکه مورد استفاده قرار گیرد، از بین رفتن یک سرور وب را نیز به دلیل فعال بودن چندین سرور، به خوبی مدیریت میکند. در شکل ۱-۴ نحوه کارکرد یک لودبالانسر به صورت تصویری نمایش داده شده است.
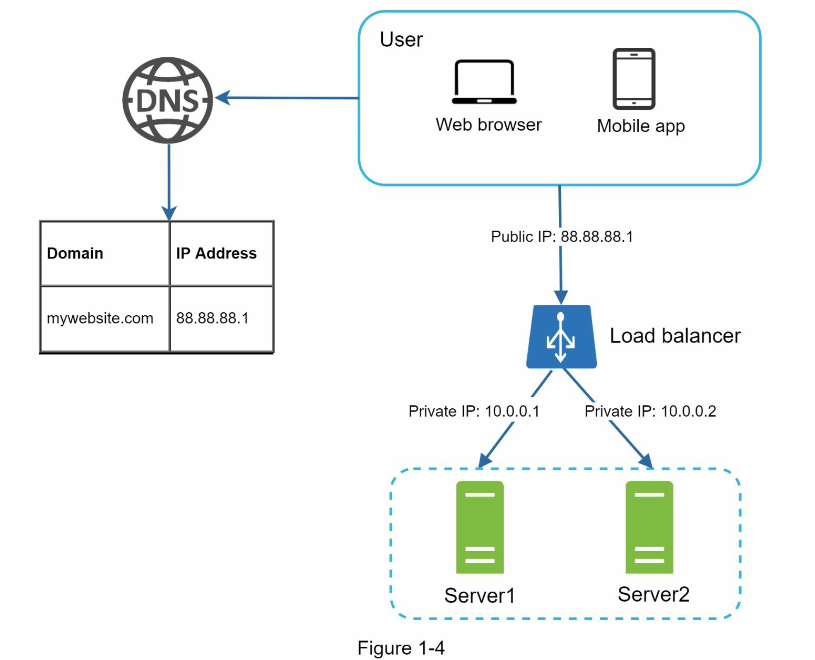
همانطور که در شکل ۱-۴ نشان داده شده است، کاربران ابتدا به IP عمومی لودبالانسر متصل شده و باربالانسر سپس درخواست کاربر را به یکی از سرورهای وب در مجموعهای که لودبالانسر تعریف کرده است، منتقل میکند. با این تنظیم، سرورهای وب دیگر قابل دسترسی مستقیم توسط کاربران نیستند و تمامی ترافیک ورودی به سایت از طریق لودبالانسر عبور میکند. برای افزایش امنیت، برای ارتباط بین سرورها از آیپیهای خصوصی استفاده میشود که تنها بین سرورهایی در یک شبکه مشابه قابل دسترسی است و در اینترنت قابل دسترسی نیستند. لودبالانسر از آدرسهای آیپی خصوصی برای ارتباط با سرورهای وب استفاده میکند. در نتیجه، با استفاده از لودبالانسر ، تمامی درخواستهای وب سرور به صورت منظم و مناسب بین سرورهای مختلف تقسیم میشوند و باعث افزایش قابلیت اطمینان، بهبود عملکرد و افزایش امنیت سایت میشود.
در طرح قبلی، همانند تصویر ۱-۳، کاربران بهصورت مستقیم به وب سرور متصل میشدند و در صورتی که وب سرور در دسترس نبود، کاربران نمیتوانستند به وبسایت دسترسی پیدا کنند. با اضافه کردن لودبالانسر ، کاربران بهصورت مستقیم به آیپی عمومی باربالانسر متصل میشوند. بعد از این که درخواست کاربر به لودبالانسر میرسد، باربالانسر بهجای فرستادن درخواست به یک وب سرور، آن را به دو وب سرور مختلف ارسال میکند. با این کار، احتمال خرابی وب سرور کاهش مییابد و در صورتی که یک وب سرور خراب شود، کاربران بهصورت خودکار به وب سرور دیگر هدایت میشوند. به علاوه، با افزودن دومین وب سرور، در دسترس بودن سرویس وب بهبود یافته و امکان استفاده از منابع افزایش مییابد.
- اگر سرور ۱ خارج از دسترس باشد، تمام ترافیک به سرور ۲ هدایت میشود و این باعث میشود وبسایت به حالت آفلاین نروید. همچنین، یک سرور وب جدید و سالم به استخر سرور اضافه خواهد شد تا بار ترافیک را توزیع کند.
- اگر ترافیک وبسایت به سرعت رشد کند و دو سرور کافی برای پردازش آن نباشد، لودبالانسر به شیوهای کاملاً مطمئن مشکل را برطرف میکند. تنها کافیست که بیشترین سرورهای وب را به پول سرور وب اضافه کنید و لودبالانسر بهطور خودکار درخواستها را به آنها هدایت خواهد کرد
در حال حاضر طبق طرح فعلی، لایه وب خوب به نظر میرسد، اما لایه داده چطور؟ زیرا طرح فعلی شامل یک پایگاه داده است، بنابراین پشتیبانی از failover و redundancy را ندارد. کپی داده پایگاه داده (database replication) یک تکنیک رایج برای حل این مشکلات است. بیایید به آن نگاهی بیندازیم.
در سیستمهای مدیریت پایگاه داده، تکنیک رپلیکیشن پایگاه داده، به طور معمول با برقراری یک رابطه master / slave بین پایگاه داده اصلی (master) و کپیهای آن (slave) استفاده میشود. اکثراً در یک سیستم رپلیکیشن پایگاه داده، پایگاه داده master تنها عملیات write را پشتیبانی میکند، در حالی که پایگاه داده slave ، نسخههایی از دادهها را از پایگاه داده master دریافت کرده و تنها عملیات خواندن دادهها را پشتیبانی میکند. این بدان معنی است که تمام دستورالعملهایی که تغییری در دادهها ایجاد میکنند، مانند insert ، delete یا update ، باید به پایگاه داده master فرستاده شوند.
بسیاری از برنامهها نیاز به تعداد خوانده شدن دادهها بیشتر از تعداد نوشتاری دارند؛ بنابراین تعداد پایگاه دادههای slave در یک سیستم رپلیکیشن پایگاه داده، معمولاً بیشتر از تعداد پایگاه دادههای مستر است. شکل 1-5، یک پایگاه داده master با چندین پایگاه داده slave را نشان میدهد.
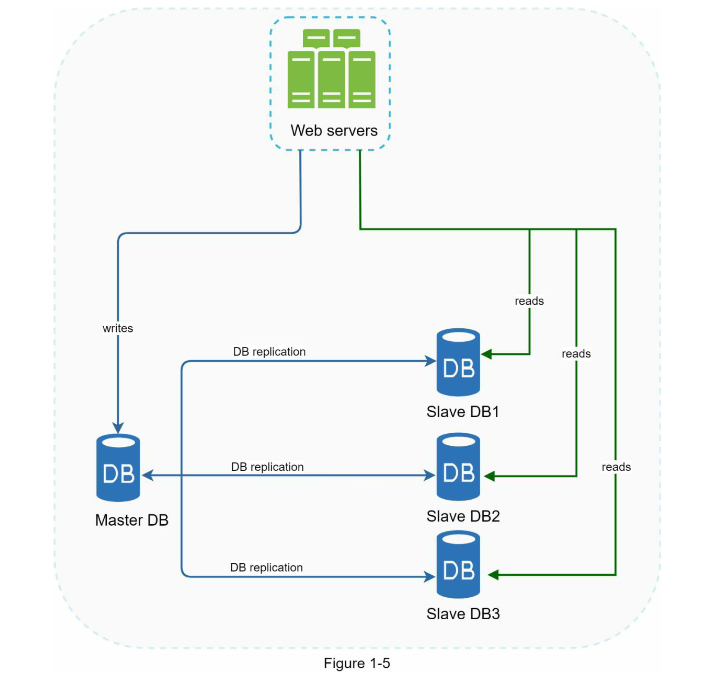
مزایای database replication
در مدیریت سیستمهای پایگاه داده، مسئلهای که ممکن است پیش آید، بیثباتی و عدم اطمینان از دسترسی به دادهها است. برای حل این مشکل، تکنیکهای متعددی مانند رپلیکیشن دیتابیس در این حوزه به کار گرفته میشوند. یکی از مزایای مهم رپلیکیشن دیتابیس، افزایش قابلیت اطمینان و کاهش نقصان در دسترسی به دادههاست. به وسیلهی رپلیکیشن، از یک دیتابیس اصلی (master) به چندین دیتابیس ثانویه (slave) دیگر دادههایی که در دیتابیس اصلی وجود دارند، کپی میشود و در دیتابیسهای ثانویه قرار میگیرد. در نتیجه، در صورت بروز هرگونه مشکل در دیتابیس اصلی، از دیتابیسهای ثانویه میتوان برای ادامه کار استفاده کرد. این روش همچنین به افزایش سرعت عملیاتها کمک میکند زیرا عملیاتهای خواندن دادهها از دیتابیسهای ثانویه انجام میشوند که در نتیجه، بار ترافیک به دیتابیس اصلی کاهش مییابد.
شکل 1-6 نشان دهنده طراحی سیستم پس از افزودن لودبالانسر و تکنیک database replication است. در این طرح، کاربران با اتصال به آدرس IP عمومی لودبالانسر، به یکی از سرورهای وب متصل میشوند. لودبالانسر با استفاده از الگوریتم خاص خود ترافیک را بین سرورهای وب متصل به خود توزیع میکند. هر سرور وب، از طریق تکنیک database replication، با یک سرور دیگر به عنوان مستر در تعامل است تا در صورت خرابی سرور master، سرور دیگر بتواند جایگزینی مناسب باشد. همچنین با اضافه کردن سرور وب جدید به سیستم، بار ترافیک به طور خودکار بین سرورهای وب جدید توزیع میشود و باعث افزایش پایداری سیستم میشود.

در این طراحی، به گونهای که در شکل 1-6 نشان داده شده است عمل میشود:
• کاربر آدرس IP لودبالانسر را از DNS دریافت میکند.
• کاربر با استفاده از این آدرس IP به لودبالانسر متصل میشود.
• درخواست HTTP به سمت سرور 1 یا سرور 2 هدایت میشود.
• سرور وب اطلاعات کاربر را از دیتابیس slave میخواند.
• سرور وب هرگونه عملیات تغییردادنی اطلاعات را به دیتابیس master ارسال میکند. این عملیات شامل عملیات نوشتن، به روزرسانی و حذف اطلاعات است.
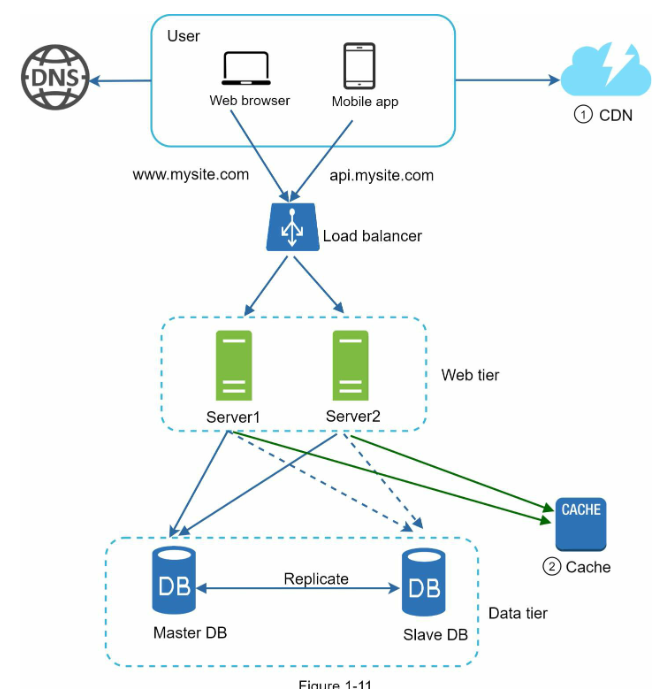
اکنون با توجه به طرح دو سطحی وب و دیتابیس، زمان بارگیری و پاسخدهی را بهبود میبخشیم. برای این کار، میتوانیم یک لایه کش (Cache) و همچنین جابجایی محتوای استاتیک (فایلهای JavaScript / CSS / تصویر / ویدیو) به شبکه تحویل محتوا (CDN) اضافه کنیم.
Cache
در واقع، کش (Cache) یک فضای ذخیرهسازی موقت است که نتیجه پاسخهایی با هزینه بالا یا دادههای مورد دسترسی مکرر را در حافظه ذخیره میکند، تا درخواستهای بعدی به سرعت تری پاسخ داده شوند. همانطور که در شکل ۱-۶ نشان داده شده است، هر بار که یک صفحه وب جدید بارگذاری میشود، یک یا چند تماس با پایگاه داده برای بازیابی دادهها انجام میشود. عملکرد برنامه به شدت تحت تاثیر تماس مکرر با پایگاه داده قرار میگیرد. کش میتواند این مشکل را بهبود بخشد.
لایه Cache
لایه کش یک لایه ذخیره سازی داده موقت است که نسبت به پایگاه داده بسیار سریعتر است. مزایای داشتن یک لایه کش جداگانه شامل بهبود عملکرد سیستم، کاهش بار کاری پایگاه داده و قابلیت مقیاس پذیری جداگانه برای لایه کش است. شکل 1-7 نشان دهنده نحوه یک نصب ممکن از یک سرور کش است:

اولین قدم در رسیدگی به درخواست، بررسی این است که آیا اطلاعات مورد نیاز در حافظه نهان (کش) موجود است یا خیر. در صورت وجود اطلاعات در کش، سرور وب آنها را به کلاینت ارسال میکند. در صورتی که اطلاعات مورد نیاز در کش وجود نداشته باشد، سرور به پایگاه داده پرس و جو میفرستد، پاسخ دریافتی را در کش ذخیره میکند و به کلاینت ارسال میکند. این استراتژی کشینگ با نام read-through cache شناخته میشود. البته استراتژی کشینگ دیگری نیز بر اساس نوع داده، اندازه و الگوی دسترسی قابل انتخاب است. یک مطالعه پیشین در این زمینه راهنمایی کننده است که چگونگی کار با استراتژیهای مختلف کشینگ را شرح میدهد.
ملاحظاتی برای استفاده از کش
استفاده از سیستم کش (Cache) در طراحی سیستم های نرم افزاری، مزایای زیادی دارد. با این حال باید در نظر داشت که برخی موارد ممکن است موجب مشکلاتی در سیستم شود. در ادامه به برخی از مهمترین نکاتی که باید در نظر گرفته شود، اشاره می کنیم:
۱. انتخاب استراتژی کش: برای داده های مختلف استراتژی کش متفاوتی میتوانید انتخاب کنید. برای مثال در صورتی که دادهها به صورت ثابت و متناوب تغییر میکنند، استراتژی کش read-through بهترین گزینه است.
۲. مدیریت حجم داده: سیستم کش به دلیل حفظ دادهها، به شدت تاثیرگذار بر روی فضای دیسک و حافظه سیستم است. لذا باید به مدیریت حجم دادهها توجه کرد و در صورت نیاز، از استراتژیهایی مانند تنظیم زمان انقضای دادهها استفاده کرد.
۳. امنیت سیستم: استفاده از سیستم کش، به معنای ذخیره سازی دادههای حساس در حافظه است. بنابراین باید از ابزارهای مناسب برای افزایش امنیت سیستم مانند رمزنگاری، استفاده کرد.
۴. روش همگامسازی دادهها: در صورتی که دادههای موجود در کش، معتبر نباشند، ممکن است سیستم به درستی کار نکند. بنابراین باید از روش همگامسازی دادهها استفاده کرد و به مدت زمان مشخصی، دادههای کش شده را بررسی و بروزرسانی کرد
به علاوه، باید در نظر داشت که سیستم کش تنها یکی از ابزارهای بهینهسازی کارایی سیستم است و برای بهبود کارایی باید سایر عواملی مانند شبکه، پهنای باند، سرعت سرورها و … نیز مورد بررسی قرار گیرد. علاوه بر این، نیاز به توسعه و پشتیبانی کش هم وجود دارد و ممکن است نیاز به انجام تغییرات در کش و دیگر اجزای سیستم باشد. بنابراین، استفاده از کش باید با دقت و با بررسی دقیق اثرات جانبی و تغییرات در سایر اجزای سیستم صورت گیرد.
استفاده از Content delivery network (CDN)
CDN به معنای شبکه توزیع محتوا (Content Delivery Network) است و به یک سرویس اینترنتی اشاره دارد که به کاربران اجازه میدهد تا محتوای وب خود را در سراسر جهان انتشار دهند. CDN از یک سری سرورهای قرارگیری در نقاط مختلف دنیا استفاده میکند تا محتوا را به صورت موثر و سریع به کاربران در نقاط مختلف دنیا ارائه دهد.
با استفاده از CDN، سرعت بارگیری صفحات وب بهبود مییابد و بار سرور اصلی کاهش مییابد. همچنین، محتوای وب در CDN از دیدگاه امنیتی نیز بهترین حالت را دارا میباشد، زیرا هنگامی که محتوای وب در CDN انتشار مییابد، در برابر حملات DDoS (حملات توزیع شده از طریق خدمات) و حملات دیگری از این قبیل محافظت میشود.
مزایای CDN
استفاده از CDN (شبکه توزیع محتوا) بسیاری از مزایا و فواید را به دنبال دارد، این مزایا عبارتند از:
۱. سرعت بارگیری سایت: با استفاده از CDN، سرعت بارگیری صفحات سایت به شدت افزایش مییابد. با اینکه سرعت اینترنت در نقاط مختلف جهان متفاوت است، اما با استفاده از CDN، محتوای سایت در نزدیکترین سرورها قرار میگیرد و بهترین سرعت بارگیری را برای کاربران فراهم میکند.
۲. کاهش بار سرور: با افزایش تعداد کاربران سایت، بار سرور اصلی سایت افزایش مییابد. با استفاده از CDN، بار سرور به سرورهای دیگر توزیع میشود و این باعث کاهش بار سرور اصلی و افزایش پایداری سایت میشود.
۳. بهبود رتبهبندی سایت در موتورهای جستجو: سرعت بارگیری سایت یکی از عوامل مهم در رتبهبندی سایت در موتورهای جستجو است. با افزایش سرعت بارگیری سایت، رتبه سایت در موتورهای جستجو بهتر میشود.
۴. بهبود امنیت سایت: CDN ها از روشهای پیشرفته امنیتی برای حفاظت از سایت در برابر حملات DDoS و انواع حملات دیگر استفاده میکنند. همچنین، بعضی از CDN ها از SSL (Secure Sockets Layer) برای رمزنگاری ارتباطات استفاده میکنند و این باعث بهبود امنیت سایت میشود.
۵. بهینهسازی محتوای وب: با استفاده از CDN، محتوای وب بهینهسازی میشود و برای کاربران در دسترس قرار میگیرد. این به معنای بهبود تجربه کاربری کاربران و افزایش تعامل با سایت است.
شکل 1-10 گردش کار CDN را نشان می دهد.
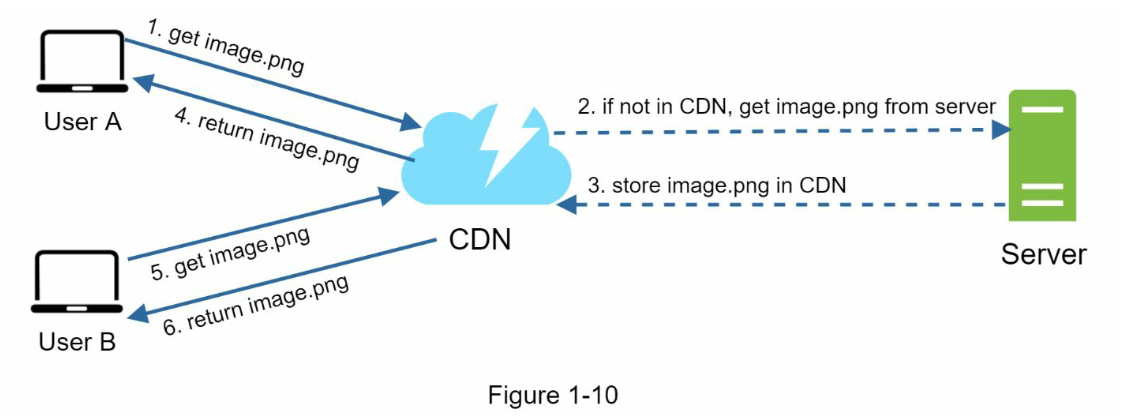
اما حالا CDN دقیقا چه کاری برای ما انجام میدهد؟ سرویس CDN یکسری سرور را بهعنوان سرورهای لبه (Edge Server) در میان کاربر و سرور اصلی سایت ما قرار میدهد. یعنی بهجای اینکه درخواست کاربر مستقیما به سمت سرور اصلی سایت برسد. ابتدا درخواست به سرور لبه میرسد و سپس همان درخواست از سرور لبه به سرور اصلی سایت انتقال داده میشود. حالا در این میان سرور لبه یک نسخه از پاسخ سرور اصلی به درخواست کاربر در خودش ذخیره میکند. این کار باعث میشود که اگر یک کاربر دیگر، همان درخواست را بخواهد ارسال کند. پس از رسیدن درخواستش به سرور لبه پاسخ ذخیره شده را دریافت خواهد کرد. یعنی با این کار دیگری نیازی نیست که درخواست کاربر به سمت سرور اصلی سایت ارسال شود و منابع سرور بابت پاسخگویی به درخواست اشغال شود.
جالب است بدانید تعداد این سرورهای لبه هم کم نیست. تقریبا میتوان گفت در تمام مرکز استانهای کشور، یک یا چند سرور لبه وجود دارد. در نتیجه با افزایش تعداد درخواستهای کاربران، سرور سایت شما Down نخواهد شد. چرا که درخواستهای کاربران روی سرورهای لبه توزیع میشود.
استفاده از CDN یک راه حل ایدهآل برای بهبود سرعت و کارایی بارگذاری وب سایت است. در زیر به برخی از مزایای استفاده از CDN اشاره میکنم:
۱- کاهش تأخیر: CDN به کاهش تأخیر در بارگذاری وب سایت کمک میکند، زیرا محتواهایی که در سرور CDN ذخیره میشوند، در نزدیکی کاربر قرار دارند و به طور خودکار از سروری که فاصله کمتری با کاربر دارد، بارگیری میشوند.
۲- افزایش پهنای باند: با استفاده از CDN، پهنای باند سرور اصلی بهبود مییابد زیرا بار آن به سرورهای CDN توزیع شده است. این موضوع باعث کاهش فشار و بار سرور اصلی میشود و بهبود کارایی سایت را به دنبال دارد.
۳- بهبود قابلیت دسترسی: با استفاده از سرورهای CDN، قابلیت دسترسی به سایت در مناطق دوردست و حتی در کشورهای دیگر بهبود مییابد، زیرا محتوای سایت در سرورهای CDN متعدد در سراسر جهان موجود است.
۴- کاهش هزینه: با استفاده از CDN، میتوان هزینههای مربوط به پهنای باند، تجهیزات و سرورها را کاهش داد. همچنین، با توزیع بار بین سرورهای CDN، هزینههای مربوط به تعمیر و نگهداری سرورهای اصلی نیز کاهش مییابد.
در مجموع، استفاده از CDN بهبود کارایی وب سایت را به دنبال دارد و میتواند به کاهش تأخیر، افزایش پهنای باند، بهبود قابلیت دسترسی و کاهش هزینه منجر شود
شکل 1-11 طراحی پس از افزودن CDN و Cache را نشان می دهد.
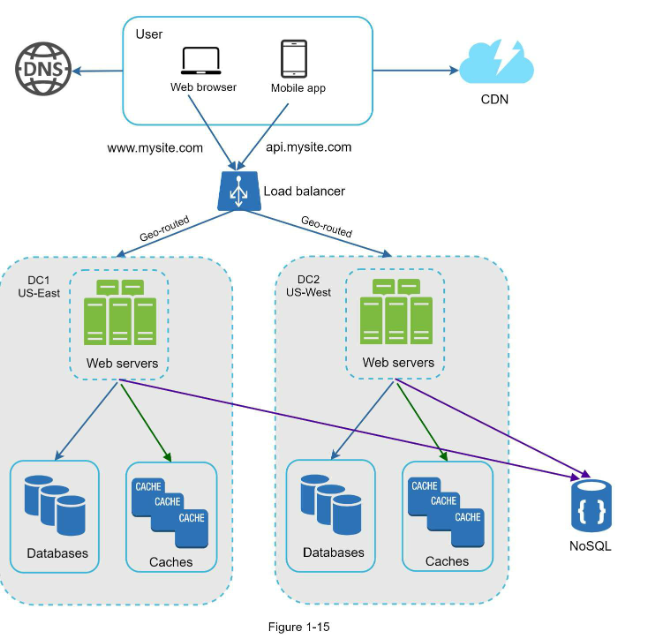
بررسی دیتاسنتر
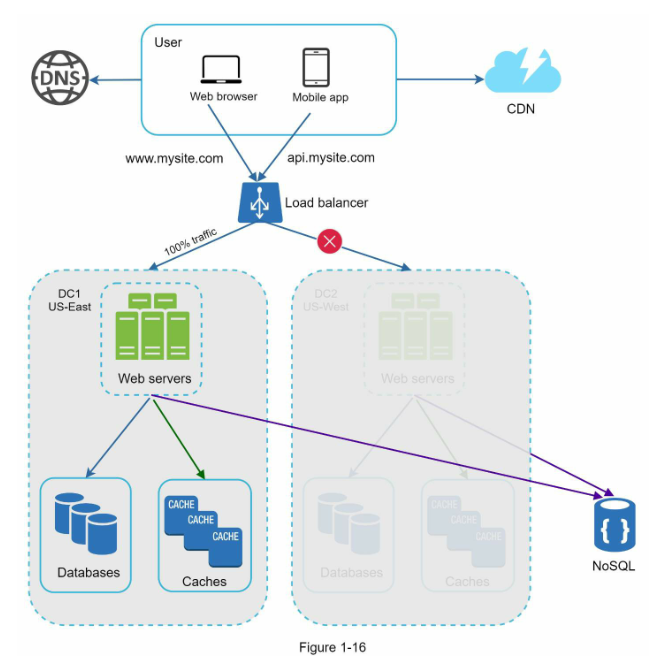
شکل ۱-۱۵ یک نمونه از استراکچر با دو دیتاسنتر نشان میدهد.
در صورت وقوع هر گونه خرابی مهم در دیتاسنتر، ما تمام ترافیک را به یک دیتاسنتر سالم هدایت میکنیم. در شکل ۱-۱۶، دیتاسنتر ۲ (غرب آمریکا) آفلاین است و تمام ترافیک به دیتاسنتر ۱ (شرق آمریکا) هدایت میشود.
Message queue
صف پیام یا Message Queue یک قطعه دائمی است که در حافظه ذخیره شده و ارتباطات ناهمزمان را پشتیبانی میکند. این سرویس به عنوان یک بافر عمل میکند و درخواستهای ناهمزمان را توزیع میکند. معماری اولیه یک صف پیام ساده است. سرویسهای ورودی، که تولیدکنندگان/انتشاردهندگان نامیده میشوند، پیامها را ایجاد کرده و آنها را به صف پیام منتشر میکنند. سرویسها یا سرورهای دیگر، که مشترک/مصرف کنندگان نامیده میشوند، به صف متصل میشوند و اقداماتی که توسط پیامها تعریف شده است را انجام میدهند. این مدل در شکل ۱-۱۷ نمایش داده شده است.
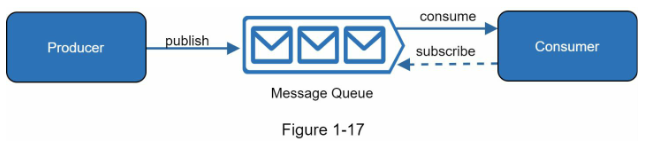
Message Queue یک ابزار قابل اعتماد و پایدار است که ارتباطات ناهمگام را پشتیبانی میکند. این سیستم به عنوان یک بافر و توزیع کننده برای درخواستهای ناهمگام عمل میکند. ساختمان پایه یک Message Queue به سادگی این است که سرویسهای ورودی، که به عنوان تولید کننده / منتشر کننده شناخته میشوند، پیامها را ایجاد کرده و آنها را در یک Message Queue منتشر میکنند. سرویسهای یا سرورهای دیگر که به عنوان مصرف کننده / مشترک مشخص میشوند، به صف وصل میشوند و عملیاتی که توسط پیامها تعریف شدهاند را انجام میدهند.
در این مقاله به بحث در مورد مراحل افزایش مقیاس سیستم برای پشتیبانی از میلیونها کاربر پرداختیم. در اینجا به این نکته اشاره شده است که توسعه سیستم در این راستا یک فرآیند چرخهای است و برای رسیدن به این هدف، نیاز به بهینهسازی سیستم و جداسازی آن به سرویسهای کوچکتر است. همچنین برای مقیاسپذیری بیشتر، استفاده از راهکارهای جدید و بهینهسازیهایی دیگر میتواند مورد نیاز باشد. در نهایت، یک خلاصه از رویکردهای مورد استفاده برای افزایش مقیاس سیستم جهت پشتیبانی از میلیونها کاربر ارائه شده است.
این چک لیست به صورت خلاصهای از روشهایی است که میتوان برای مقیاسپذیری سیستمهای وب استفاده کرد:
- حفظ عدم وجود حالت در وب تیره (web tier)، یعنی ذخیره اطلاعات در کوکیها و یا سشنها جهت تحلیل و بررسی همیشه باید بین سرورهای مختلف به اشتراک گذاشته شوند.
- ساخت تکرارپذیری در هر سطح (tier) سیستم.
- استفاده از حافظههای نهان (cache) برای ذخیرهسازی دادهها و اطلاعات به مدت طولانیتر و کاهش زمان دسترسی به دادهها در هر درخواست.
- پشتیبانی از چندین مرکز داده (data center)، جهت افزایش دسترسی و بهبود پایداری.
- قرار دادن فایلهای استاتیک (static assets) در CDN (شبکه توزیع محتوا)، برای کاهش زمان بارگذاری درخواستهای استاتیک.
- مقیاسبندی لایه داده (data tier) با استفاده از شاردینگ (sharding)، برای توزیع بار و پشتیبانی از حجم دادههای بزرگ.
- تقسیم لایهها به خدمات جداگانه (individual services)، برای جدا کردن وظایف و بهبود مقیاسپذیری و پایداری.
- پایش سیستم و استفاده از ابزارهای اتوماسیون، جهت دستیابی به بهرهوری بیشتر و جلوگیری از نواقص و خرابیها.
با رعایت این راهکارها میتوان سیستم وب خود را برای پاسخگویی به میلیونها کاربر مقیاسپذیر کرد.
منبع :System Design Interview An Insider’s Guide by Alex Xu