
دو روش برای سازماندهی دیتابیسهای رابطهای وجود دارد:
- Row Oriented
- Column Oriented (همچنین بهعنوان ستونی یا C-store شناخته میشود)
دیتابیسهای Row Oriented دیتابیسهایی هستند که دادهها را بر اساس رکورد سازماندهی میکنند و تمام دادههای مرتبط با یک رکورد را در کنار یکدیگر در حافظه نگه میدارند. دیتابیسهای Row Oriented روش سنتی سازماندهی دادهها هستند و هنوز برخی از مزایای کلیدی را برای ذخیره سریع دادهها ارائه میدهند. آنها برای خواندن و نوشتن سطرها بهینه شدهاند.
دیتابیسهای رایج Row Oriented
- Postgres
- MySQL
دیتابیسهای Column Oriented دیتابیسهایی هستند که دادهها را بر اساس فیلد سازماندهی میکنند و همه دادههای مرتبط با یک فیلد را در کنار یکدیگر در حافظه نگه میدارند. دیتابیسهای Column Oriented محبوبیت زیادی پیدا کردهاند و مزایای عملکردی را برای کوئری دادهها ارائه میدهند. آنها برای خواندن و محاسبه کارآمد بر روی ستونها بهینه شدهاند.
دیتابیسهای رایج Column Oriented
- Redshift
- BigQuery
- Snowflake
دیتابیسهایRow Oriented
سیستمهای مدیریت دیتابیس سنتی برای ذخیره دادهها ایجاد شدهاند. آنها برای خواندن و نوشتن یک ردیف از دادهها بهینه شده در یک فروشگاه ردیف یا دیتابیس سطر گرا، دادهها سطر به سطر ذخیره میشوند، بهطوریکه اولین ستون یک ردیف در کنار آخرین ستون ردیف قبلی قرار میگیرد.
بهعنوانمثال، بیایید این دادههای Facebook_Friends را در نظر بگیریم
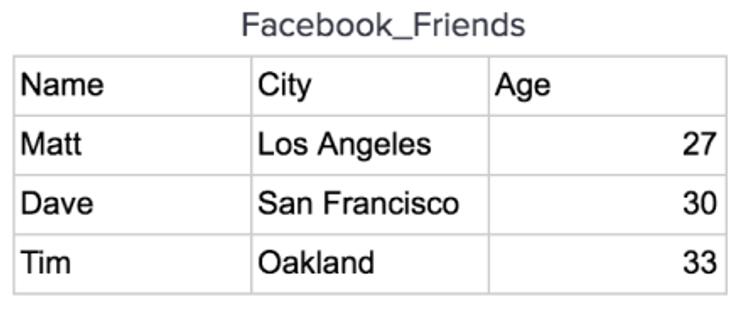
این دادهها در یک دیسک در یک دیتابیس Row Oriented به ترتیب ردیف بهردیف مانند زیر ذخیره میشوند:

این به دیتابیس اجازه میدهد تا یک ردیف را بهسرعت بنویسد، زیرا تنها کاری که برای نوشتن روی آن باید انجام شود، چسباندن یک ردیف دیگر به انتهای داده است.
نوشتن در دیتابیس Row Oriented
بیایید از دادههای ذخیره شده در دیتابیس استفاده کنیم

اگر بخواهیم یک رکورد جدید اضافه کنیم:

ما فقط میتوانیم آن را به انتهای دادههای فعلی اضافه کنیم:

دیتابیسهای Row Oriented هنوز هم معمولاً برای برنامههای کاربردی سبک پردازش تراکنش آنلاین (OLTP) استفاده میشوند زیرا میتوانند نوشتههای روی دیتابیس را بهخوبی مدیریت کنند. بااینحال، یکی دیگر از موارد استفاده از دیتابیسهای، تجزیهوتحلیل دادههای درون آنها است. این موارد استفاده از پردازش تحلیلی آنلاین (OLAP) به دیتابیسی نیاز دارند که بتواند از کوئری موقت دادهها پشتیبانی کند. اینجاست که دیتابیسهای Row Oriented کندتر از دیتابیسهای C-store هستند.
خواندن از دیتابیسهای Row Oriented
دیتابیسهای Row Oriented در بازیابی یک ردیف یا مجموعهای از ردیفها سریع عمل میکنند، اما هنگام اجرای یک Aggregation ، دادههای اضافی (ستونها) را به حافظه میآورند که کندتر از انتخاب ستونهایی است که روی آنها تجمیع را انجام میدهید.
علاوه بر این، تعداد دیسکهایی که در دیتابیس Row Oriented ممکن است نیاز به دسترسی داشته باشد معمولاً بیشتر است.
دادههای اضافی در Memory
فرض کنید میخواهیم مجموع سنها را از دادههای Facebook_Friends دریافت کنیم. برای انجام این کار، ما باید هر ۹ قطعه از این دادهها را در حافظه بارگذاری کنیم تا سپس دادههای مربوطه را برای انجام Aggregation بیرون بکشیم.

این زمان محاسباتی تلف شده است.
تعداد دیسکهای قابلدسترسی
بیایید فرض کنیم یک دیسک فقط میتواند بهاندازه کافی بایت داده را برای سه ستون در هر دیسک ذخیره کند. در دیتابیس Row Oriented جدول بالا بهصورت زیر ذخیره میشود:
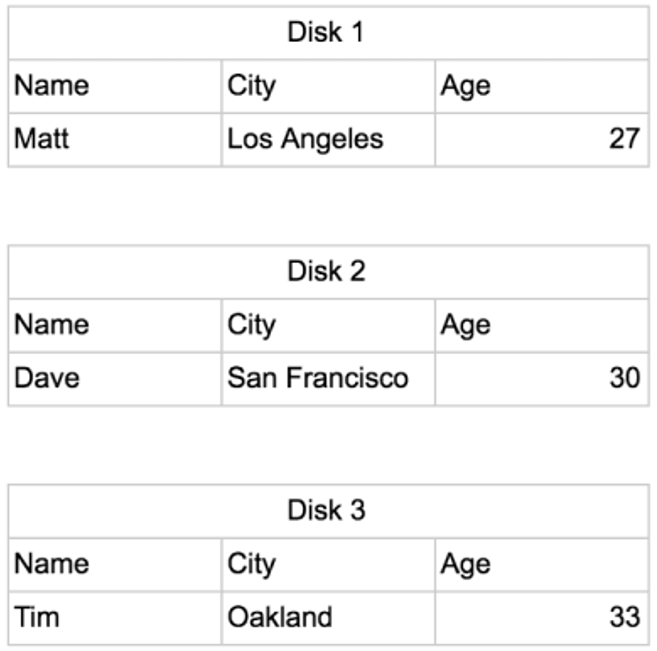
برای بهدستآوردن sum سنین افراد، سیستم باید از طریق هر سه دیسک و هر سه ستون در هر دیسک بهمنظور ایجاد این کوئری نگاه کند.
بنابراین، میتوانیم ببینیم که درحالیکه افزودن دادهها به یک دیتابیس Row Oriented سریع و آسان است، دریافت دادهها از آن میتواند نیاز به حافظه اضافی برای استفاده و دسترسی به چندین دیسک داشته باشد.
دیتابیسهای Column Oriented
Data Warehouses ها بهمنظور پشتیبانی از تجزیهوتحلیل دادهها ایجاد شدند. این نوع از دیتابیسها برای خواندن بهینهسازی شدهاند.
در یک دیتابیس C-Store، Columnar یا Column Oriented، دادهها بهگونهای ذخیره میشوند که هر سطر از یک ستون در کنار سایر ردیفهای همان ستون باشد.
بیایید دوباره به همان مجموعهداده نگاه کنیم و ببینیم چگونه در یک دیتابیس Column Oriented ذخیره میشود.
یک جدول یک ستون در یکزمان به ترتیب ردیف بهردیف ذخیره میشود:

نوشتن در دیتابیسهای Column Oriented
اگر بخواهیم یک رکورد جدید اضافه کنیم:

ما باید در اطراف دادهها حرکت کنیم تا هر ستون را به جایی که باید باشد اضافه کنیم.

اگر دادهها روی یک دیسک ذخیره میشد، همان مشکل حافظه اضافی مانند یک دیتابیس Row Oriented را داشت، زیرا باید همه چیز را به حافظه بیاورد. بااینحال، دیتابیسهای Column Oriented هنگامی که روی دیسکهای جداگانه ذخیره میشوند، مزایای قابلتوجهی خواهند داشت.
اگر جدول بالا را در سه ستون دیسک داده با محدودیت مشابه قرار دهیم، آنها به شکل زیر ذخیره میشوند:
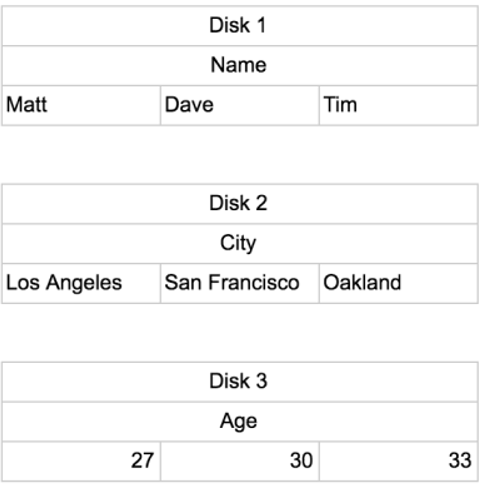
خواندن از دیتابیس Column Oriented
برای بهدستآوردن مجموع سنها، کامپیوتر فقط باید به یک دیسک (دیسک ۳) رفته و تمام مقادیر داخل آن را جمع کند. نیازی به حافظه اضافی نیست و به حداقل تعداد دیسک دسترسی دارد.
درحالیکه این یک کمی سادهسازی است، اما نشان میدهد که با سازماندهی دادهها بر اساس ستون، تعداد دیسکهایی که باید بازدید شوند کاهش مییابد و مقدار دادههای اضافی که باید در حافظه نگهداری شود به حداقل میرسد. این امر سرعت کلی محاسبات را تا حد زیادی افزایش میدهد.