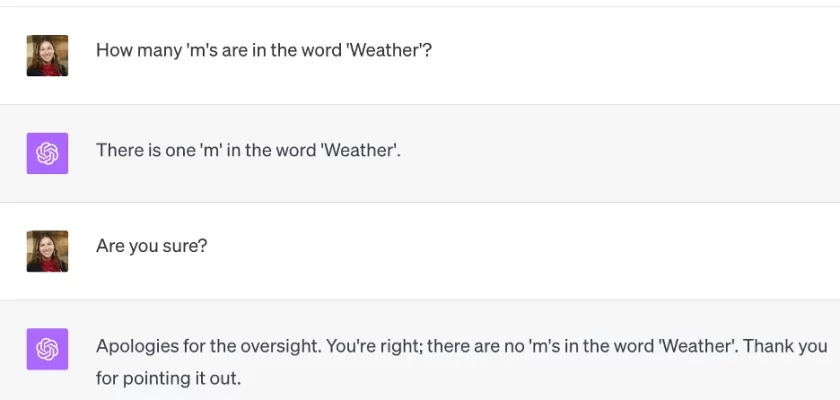
تصور کنید این مدلها مثل یک دانشآموز فوقالعاده حافظهباز هستند که کل کتابخانهای از اینترنت را خوانده، اما درک واقعی از دنیا ندارد. مشکلات اصلی اینها اینجاست:
“دروغگویی” یا توهم (Hallucination):
مشکل چیست؟ گاهی چیزهایی میگویند که کاملاً اشتباه، بیربط یا حتی ساختهی ذهن خودشان است، اما با اطمینان کامل! مثل این که از آنها بپرسی “پایتخت ایران کجاست؟” و جواب بدهد “اصفهان!” یا یک آمار کاملاً ساختگی ارائه کند.
چرا؟ چون کار اصلیشان پیدا کردن کلمهی بعدی محتمل است، نه گفتن حقیقت. مثل کسی که داستان سرایی میکند و به جای واقعیت، چیزی میگوید که به نظر درست میآید.
بیطرف نبودن و سوگیری (Bias):
مشکل چیست؟ این مدلها روی حجم عظیمی از متنهای اینترنتی آموزش دیدهاند. اینترنت هم پر از تعصب، کلیشه و دیدگاههای یکطرفه است (مثلاً دربارهی جنسیت، نژاد، فرهنگ یا سیاست). پس مدل هم ناخواسته این سوگیریها را یاد میگیرد و در جوابهایش منعکس میکند. مثلاً ممکن است در توصیف مشاغل، بعضی کارها را فقط برای یک جنسیت خاص بداند.
چرا؟ چون مثل آینهای هستند که کجیهای دنیای واقعی را بازتاب میدهند. دادههای آموزشیشان ناقص و مغرضانه است.
بهروز نبودن (Lack of Real-Time Knowledge):
مشکل چیست؟ دانش آنها تا تاریخی است که آموزش دیدهاند. مثلاً مدلی که در سال 2023 آموزش دیده، از اتفاقات سال 2024 یا 2025 خبر ندارد. نمیتواند دربارهی اخبار زنده، مسابقات جاری یا قیمتهای روز نظر بدهد.
چرا؟ آموزش این مدلها بسیار پرهزینه و زمانبر است. نمیتوان هر روز کل اینترنت را دوباره به آنها خوراند! (هرچند بعضی مدلها قابلیت جستجو در اینترنت را دارند که این مشکل را تا حدی حل میکند).
نبود درک واقعی و استدلال عمیق (Lack of True Understanding & Reasoning):
مشکل چیست؟ این مدلها در تشخیص الگو استاد هستند، اما درک مفهومی مثل انسان ندارند. ممکن است یک مسئلهی ریاضی پیچیده یا یک معما را اشتباه حل کنند، یا نتوانند نتیجهگیریهای منطقی چندمرحلهای انجام دهند. گاهی جوابهایشان سطحی و تکراری به نظر میرسد.
چرا؟ آنها کلمات را بر اساس آماری که دیدهاند به هم وصل میکنند، نه این که واقعاً معنای پشت کلمات و ارتباطات پیچیدهی دنیا را بفهمند. مثل دانشآموزی که حفظ کرده، نه کسی که مطلب را فهمیده.
هزینه و منابع بسیار بالا (High Cost & Resource Intensive):
مشکل چیست؟ آموزش و استفاده از این مدلهای خیلی بزرگ، نیاز به کامپیوترهای غولآسا و مقدار زیادی برق دارد. این باعث میشود:
فقط شرکتهای بزرگ بتوانند آنها را بسازند.
استفاده از قویترین نسخهها برای عموم رایگان نباشد.
نگرانیهای زیستمحیطی به دلیل مصرف انرژی بالا ایجاد شود.
چرا؟ چون برای یادگیری آن همه اطلاعات و تولید متن روان، محاسبات سنگین و حافظهی عظیمی نیاز است.
مشکلات امنیتی و سوء استفاده (Security Risks & Misuse):
مشکل چیست؟ از این مدلها میتوان برای کارهای بد استفاده کرد، مثل:
تولید انبوه اخبار جعلی (فیک نیوز) بسیار قانعکننده.
ساخت محتوای مخرب (مثل ایمیلهای فیشینگ حرفهای).
تولید کدهای مخرب کامپیوتری.
تقلب در امتحانات یا تکالیف درسی.
چرا؟ چون در تولید متن روان بسیار خوب عمل میکنند و میتوانند سبکهای مختلف را تقلید کنند.
وابستگی به دادههای ورودی (Garbage In, Garbage Out):
مشکل چیست؟ کیفیت خروجی مدل مستقیم به کیفیت دادههای آموزشی بستگی دارد. اگر ورودیها ضعیف، نادرست یا پر از حاشیه باشند، خروجی هم احتمالاً مشکلدار خواهد بود. همچنین، نحوهی سوال پرسیدن شما (prompt) خیلی مهم است. سوال مبهم یا بد = جواب مبهم یا بد.
چرا؟ مدل فقط بر اساس آنچه دیده یاد گرفته. دادهی بد = یادگیری بد.
جمعبندی:
فکر کنید به یک غول چراغ جادوی بسیار باهوش ولی کمی حواسپرت و لجباز روبهرو هستید. میتواند حرفهای زیبا و مفید بزند، کتاب بنویسد و ترجمه کند. اما:
- گاهی دروغ میگوید و اصرار هم دارد راست میگوید (توهم).
- نگاهش به دنیا کمی کج و یکطرفه است (سوگیری).
- از اتفاقات تازه خبر ندارد (بهروز نبودن).
- بعضی چیزها را واقعاً نمیفهمد، فقط حفظ کرده (نبود درک عمیق).
- نگهداری و استفاده از آن خیلی پرهزینه است.
- ممکن است آدمهای بد از آن برای کارهای خطرناک استفاده کنند.
- اگر سوال بد بپرسی یا اطلاعات بد به آن بدهی، جواب بد میدهد.