
فصل ۴ استدلال کرد که ماژولها باید عمیق باشند. این فصل و چند فصل بعدی، تکنیکهایی برای ساختن ماژولهای عمیق را بررسی میکنند.
۵.۱ نهانسازی اطلاعات
مهمترین تکنیک برای دستیابی به ماژولهای عمیق، نهانسازی اطلاعات است. این تکنیک نخستین بار توسط دیوید پارناس توصیف شد. ایدهی اصلی این است که هر ماژول باید تعداد کمی دانش را در خود کپسوله کند که نشاندهندهی تصمیمات طراحی هستند. این دانش در پیادهسازی ماژول گنجانده شده اما در رابط کاربری آن ظاهر نمیشود، بنابراین برای ماژولهای دیگر قابل مشاهده نیست.
اطلاعات نهانشده درون یک ماژول معمولاً شامل جزئیاتی دربارهی نحوهی پیادهسازی یک سازوکار هستند. در اینجا چند مثال از اطلاعاتی که ممکن است درون یک ماژول نهان شوند آورده شده:
- نحوهی ذخیرهسازی اطلاعات در یک درخت B و چگونگی دسترسی مؤثر به آن
- نحوهی شناسایی بلوک دیسک فیزیکی مربوط به هر بلوک منطقی در یک فایل
- نحوهی پیادهسازی پروتکل شبکهی TCP
- نحوهی زمانبندی تردها در یک پردازندهی چند هستهای
- نحوهی تجزیهی اسناد JSON
اطلاعات نهان شامل ساختارهای داده و الگوریتمهای مربوط به سازوکار است. همچنین میتواند شامل جزئیات سطح پایین مانند اندازهی یک صفحه، و مفاهیم سطح بالاتر و انتزاعیتر مانند فرضی که بیشتر فایلها کوچک هستند باشد.
نهانسازی اطلاعات به دو روش پیچیدگی را کاهش میدهد. اول، رابط ماژول را ساده میکند. رابط بازتابی از یک دیدگاه سادهتر و انتزاعیتر از عملکرد ماژول است و جزئیات را پنهان میکند؛ این باعث کاهش بار شناختی توسعهدهندگانی میشود که از ماژول استفاده میکنند. برای مثال، توسعهدهندهای که از یک کلاس درخت B استفاده میکند نیازی به نگرانی در مورد بهترین مقدار گرهها یا چگونگی متعادل نگه داشتن درخت ندارد.
دوم، نهانسازی اطلاعات باعث میشود سیستم راحتتر تکامل یابد. اگر اطلاعاتی پنهان باشد، هیچ وابستگی خارج از ماژول نسبت به آن وجود ندارد، بنابراین تغییرات طراحی مربوط به آن تنها یک ماژول را تحت تأثیر قرار میدهد. برای مثال، اگر پروتکل TCP تغییر کند (مثلاً برای معرفی یک سازوکار جدید کنترل ازدحام)، پیادهسازی پروتکل باید تغییر کند، اما نباید تغییری در کدهای سطح بالاتر که از TCP برای ارسال و دریافت داده استفاده میکنند نیاز باشد.
هنگام طراحی یک ماژول جدید، باید به دقت فکر کنید که چه اطلاعاتی میتوان در آن ماژول پنهان کرد. اگر بتوانید اطلاعات بیشتری را پنهان کنید، احتمالاً میتوانید رابط ماژول را سادهتر کنید، و این باعث میشود ماژول عمیقتر باشد.
نکته: مخفی کردن متغیرها و متدها در یک کلاس با اعلام آنها به صورت خصوصی (private) همان نهانسازی اطلاعات نیست. عناصر خصوصی میتوانند به نهانسازی اطلاعات کمک کنند، چون دسترسی مستقیم به آنها را از خارج کلاس غیرممکن میکنند. اما اطلاعات مربوط به آن عناصر خصوصی ممکن است از طریق متدهای عمومی مانند getter و setter فاش شوند. در این صورت، ماهیت و نحوهی استفاده از متغیرها به همان اندازهای در معرض دید هستند که گویی متغیرها عمومی بودهاند.
بهترین نوع نهانسازی اطلاعات زمانی است که اطلاعات کاملاً درون یک ماژول پنهان شده باشند، به طوری که برای کاربران ماژول نامربوط و نامرئی باشند. با این حال، نهانسازی جزئی نیز ارزشمند است. برای مثال، اگر یک ویژگی خاص یا اطلاعات خاص فقط توسط چند کاربر یک کلاس نیاز باشد، و از طریق متدهای جداگانه به آن دسترسی یابند به طوری که در موارد رایج قابل مشاهده نباشد، آنگاه آن اطلاعات تا حد زیادی پنهان شدهاند. چنین اطلاعاتی وابستگیهای کمتری نسبت به اطلاعاتی که برای همهی کاربران کلاس قابل مشاهده هستند ایجاد میکنند.
۵.۲ نشت اطلاعات
مخالف نهانسازی اطلاعات، نشت اطلاعات است. نشت اطلاعات زمانی رخ میدهد که یک تصمیم طراحی در چندین ماژول منعکس شود. این باعث ایجاد وابستگی بین ماژولها میشود: هرگونه تغییر در آن تصمیم طراحی مستلزم تغییر در همهی ماژولهای درگیر است.
اگر یک قطعه اطلاعات در رابط کاربری یک ماژول منعکس شود، آنگاه طبق تعریف، این اطلاعات نشت پیدا کردهاند؛ بنابراین، رابطهای سادهتر معمولاً با نهانسازی بهتر اطلاعات همبستگی دارند. با این حال، اطلاعات حتی اگر در رابط ماژول ظاهر نشوند هم میتوانند نشت پیدا کنند.
فرض کنید دو کلاس دانش مربوط به یک فرمت فایل خاص را دارند (شاید یکی از کلاسها فایلها را به آن فرمت بخواند و کلاس دیگر آنها را بنویسد). حتی اگر هیچکدام از این کلاسها آن اطلاعات را در رابط خود افشا نکنند، هر دو به آن فرمت فایل وابستهاند: اگر فرمت تغییر کند، هر دو کلاس باید تغییر کنند. این نوع نشت پنهانی از طریق «در پشتی» از نشت از طریق رابط بدتر است، چون آشکار نیست.
نشت اطلاعات یکی از مهمترین نشانههای هشداردهنده در طراحی نرمافزار است. یکی از بهترین مهارتهایی که میتوانید بهعنوان یک طراح نرمافزار یاد بگیرید، داشتن حساسیت بالا نسبت به نشت اطلاعات است. اگر با نشت اطلاعات بین کلاسها مواجه شدید، از خود بپرسید: «چگونه میتوانم این کلاسها را دوباره سازماندهی کنم تا این قطعه دانش فقط بر یک کلاس تأثیر بگذارد؟»
اگر کلاسهای درگیر نسبتاً کوچک و به اطلاعات نشتیافته وابسته باشند، ممکن است منطقی باشد که آنها را با هم ترکیب کنیم. یک رویکرد دیگر این است که اطلاعات را از همه کلاسهای درگیر بیرون بکشیم و یک کلاس جدید بسازیم که فقط آن اطلاعات را کپسوله کند. با این حال، این رویکرد تنها در صورتی مؤثر است که بتوانید یک رابط ساده برای آن پیدا کنید که جزئیات را انتزاع کند؛ اگر کلاس جدید بیشتر دانش را از طریق رابط خود افشا کند، آنگاه ارزش چندانی نخواهد داشت (در واقع فقط نشت از در پشتی را با نشت از طریق رابط جایگزین کردهاید).
پرچم قرمز: نشت اطلاعات
نشت اطلاعات زمانی رخ میدهد که یک دانش مشخص در چندین محل مورد استفاده قرار گیرد، مثلاً دو کلاس متفاوت که هر دو فرمت یک نوع خاص از فایل را درک میکنند.
۵.۳ تجزیهی زمانی (Temporal decomposition)
یکی از علل رایج نشت اطلاعات، سبک طراحیای است که من آن را تجزیهی زمانی مینامم. در تجزیهی زمانی، ساختار یک سیستم مطابق با ترتیب زمانیای است که عملیات در آن انجام میشود.
فرض کنید یک اپلیکیشن، فایلی با فرمت خاصی را میخواند، محتوای آن را تغییر میدهد و سپس دوباره آن را مینویسد. در طراحی مبتنی بر تجزیهی زمانی، این اپلیکیشن ممکن است به سه کلاس تقسیم شود: یکی برای خواندن فایل، دیگری برای اعمال تغییرات، و سومی برای نوشتن نسخهی جدید.
هم خواندن فایل و هم نوشتن آن نیاز به دانش در مورد فرمت فایل دارند که این باعث نشت اطلاعات میشود. راهحل این است که مکانیزمهای اصلی برای خواندن و نوشتن فایلها را در یک کلاس واحد ترکیب کنیم. این کلاس در هر دو مرحلهی خواندن و نوشتن اپلیکیشن استفاده خواهد شد.
افتادن در دام تجزیهی زمانی آسان است، چون هنگام کدنویسی، ترتیب انجام عملیات اغلب در ذهن شماست. اما بیشتر تصمیمات طراحی در طول عمر اپلیکیشن در زمانهای مختلف ظاهر میشوند؛ در نتیجه، تجزیهی زمانی اغلب منجر به نشت اطلاعات میشود.
ترتیب معمولاً اهمیت دارد، بنابراین در جایی از اپلیکیشن منعکس خواهد شد. اما نباید این ترتیب در ساختار ماژولها منعکس شود، مگر اینکه آن ساختار با نهانسازی اطلاعات سازگار باشد (مثلاً مراحل مختلف از اطلاعات کاملاً متفاوتی استفاده کنند).
هنگام طراحی ماژولها، تمرکز خود را بر دانشی بگذارید که برای انجام هر کار لازم است، نه ترتیب انجام آنها.
پرچم قرمز: تجزیهی زمانی
در تجزیهی زمانی، ترتیب اجرای عملیات در ساختار کد منعکس میشود: عملیاتهایی که در زمانهای مختلف اتفاق میافتند، در متدها یا کلاسهای مختلف قرار میگیرند. اگر یک دانش خاص در چندین نقطه از اجرای برنامه مورد استفاده قرار گیرد، آن دانش در چند محل کد تکرار میشود، که منجر به نشت اطلاعات خواهد شد.
۵.۴ مثال: سرور HTTP
برای نشان دادن مسائل مربوط به نهانسازی اطلاعات، بیایید تصمیمات طراحیای را بررسی کنیم که توسط دانشجویانی که در یک دورهی طراحی نرمافزار، پروتکل HTTP را پیادهسازی کردهاند، گرفته شدهاند. دیدن هم نکات مثبت کارشان و هم جاهایی که با مشکل مواجه شدهاند مفید است.
HTTP یک سازوکار است که مرورگرهای وب از آن برای ارتباط با سرورهای وب استفاده میکنند. وقتی کاربر روی لینکی در مرورگر کلیک میکند یا فرمی را ارسال میکند، مرورگر از HTTP برای ارسال یک درخواست از طریق شبکه به یک سرور وب استفاده میکند. زمانی که سرور درخواست را پردازش کرد، یک پاسخ به مرورگر ارسال میکند؛ پاسخ معمولاً شامل یک صفحهی جدید وب برای نمایش است.
پروتکل HTTP فرمت درخواستها و پاسخها را مشخص میکند، که هر دو به صورت متنی نمایش داده میشوند. شکل ۵.۱ یک نمونه درخواست HTTP را نشان میدهد که مربوط به ارسال فرم است. از دانشجویان خواسته شده بود که یک یا چند کلاس پیادهسازی کنند تا دریافت درخواستهای HTTP ورودی و ارسال پاسخها برای سرورهای وب را آسان کنند.
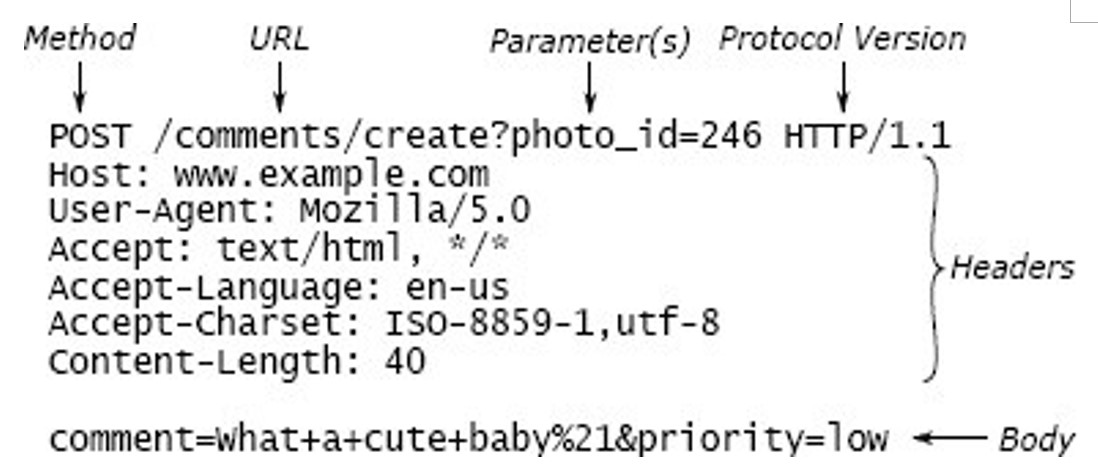
img 5.1
شکل ۵.۱: یک درخواست POST در پروتکل HTTP شامل متنی است که از طریق یک سوکت TCP ارسال میشود. هر درخواست شامل یک خط اولیه، مجموعهای از هدرها که با یک خط خالی خاتمه مییابد، و بدنهای اختیاری است.
خط اولیه شامل نوع درخواست (POST برای ارسال دادهی فرم استفاده میشود)، یک URL که عملیاتی را مشخص میکند (/comments/create) به همراه پارامترهای اختیاری (مثلاً photo_id=246) و نسخهی پروتکل HTTP است که فرستنده استفاده میکند.
هر خط هدر شامل یک نام مانند Content-Length و مقدار آن است. در این درخواست، بدنه شامل پارامترهای اضافی مثل comment و priority میباشد.
۵.۵ مثال: کلاسهای بیشازحد
رایجترین اشتباهی که دانشجویان مرتکب شدند، تقسیم کدشان به تعداد زیادی کلاس کمعمق بود که این باعث نشت اطلاعات بین کلاسها شد.
یک تیم از دو کلاس مختلف برای دریافت درخواستهای HTTP استفاده کرد؛ کلاس اول درخواست را از اتصال شبکه خوانده و آن را به یک رشته تبدیل میکرد، و کلاس دوم آن رشته را تجزیه میکرد. این نمونهای از تجزیهی زمانی است («اول درخواست را میخوانیم، سپس آن را تجزیه میکنیم»).
نشت اطلاعات رخ داد چون خواندن یک درخواست HTTP بدون تجزیهی بخش زیادی از پیام ممکن نیست؛ بهعنوانمثال، هدر Content-Length طول بدنهی درخواست را مشخص میکند، بنابراین برای محاسبهی طول کل درخواست، هدرها باید تجزیه شوند. در نتیجه، هر دو کلاس باید بیشتر ساختار درخواستهای HTTP را درک میکردند، و کد مربوط به تجزیه در هر دو کلاس تکرار شده بود.
این رویکرد همچنین پیچیدگی بیشتری برای کد فراخوان ایجاد میکرد، چون مجبور بود دو متد در دو کلاس مختلف را به ترتیب خاصی فراخوانی کند تا درخواست را دریافت کند.
از آنجا که این دو کلاس اطلاعات زیادی را به اشتراک میگذاشتند، بهتر بود که آنها را در یک کلاس واحد ادغام کنیم که هم خواندن درخواست و هم تجزیهی آن را انجام دهد. این کار نهانسازی اطلاعات را بهبود میبخشد، چرا که تمام دانش مربوط به فرمت درخواست را در یک کلاس ایزوله میکند و همچنین رابط سادهتری را در اختیار کدهای فراخوان قرار میدهد (تنها یک متد برای فراخوانی).
این مثال یک اصل کلی در طراحی نرمافزار را نشان میدهد: نهانسازی اطلاعات اغلب با کمی بزرگتر کردن کلاسها بهبود مییابد.
یکی از دلایل انجام این کار، جمعآوری تمام کدهای مرتبط با یک قابلیت خاص (مثل تجزیهی یک درخواست HTTP) در یکجا است تا کلاس حاصل، تمام کدهای مربوط به آن قابلیت را در خود داشته باشد.
دلیل دوم برای افزایش اندازهی کلاس، ارتقاء سطح رابط است؛ برای مثال، بهجای داشتن چندین متد جداگانه برای هر مرحله از یک محاسبه، یک متد منفرد داشته باشید که کل محاسبه را انجام دهد. این کار میتواند منجر به یک رابط سادهتر شود.
هر دوی این مزایا در مثال بالا قابل مشاهده است: ترکیب دو کلاس باعث میشود تمام کد مربوط به تجزیهی یک درخواست HTTP در یک کلاس گرد هم آید، و دو متد قابل مشاهده از بیرون جای خود را به یک متد بدهند. کلاس ترکیبشده نسبت به کلاسهای اولیه عمیقتر است.
البته ممکن است در بزرگ کردن کلاسها زیادهروی شود (مثلاً یک کلاس برای کل اپلیکیشن). فصل ۹ شرایطی را بررسی خواهد کرد که در آن تقسیم کد به چند کلاس کوچکتر منطقی است.
۵.۶ مثال: مدیریت پارامترهای HTTP
بعد از اینکه یک درخواست HTTP توسط سرور دریافت شد، سرور نیاز دارد به برخی از اطلاعات درون آن درخواست دسترسی پیدا کند.
کدی که درخواست شکل ۵.۱ را مدیریت میکند، ممکن است نیاز داشته باشد مقدار پارامتر photo_id را بداند.
پارامترها میتوانند در خط اول درخواست (مثل photo_id در شکل ۵.۱) یا گاهی در بدنهی آن (مثل comment و priority) مشخص شوند. هر پارامتر دارای یک نام و یک مقدار است.
مقادیر پارامترها با استفاده از رمزگذاری خاصی به نام رمزگذاری URL (URL encoding) ذخیره میشوند؛ برای مثال، در مقدار comment در شکل ۵.۱، علامت + نمایانگر فاصله (space) است، و %21 به جای علامت تعجب (!) استفاده میشود.
برای پردازش یک درخواست، سرور نیاز دارد به مقادیر برخی پارامترها (در فرم رمزگشاییشده) دسترسی پیدا کند.
بیشتر پروژههای دانشجویی دو انتخاب خوب دربارهی مدیریت پارامترها انجام داده بودند:
۱. آنها متوجه شدند که برنامههای سرور اهمیتی نمیدهند که آیا یک پارامتر در خط ابتدایی درخواست آمده یا در بدنهی آن، بنابراین این تفاوت را از دید کدهای فراخوان پنهان کردند و پارامترهای هر دو قسمت را با هم ترکیب کردند.
۲. آنها دانش مربوط به رمزگذاری URL را نیز پنهان کردند: تجزیهگر HTTP مقادیر پارامترها را پیش از بازگرداندن آنها به سرور وب رمزگشایی میکرد، بهطوری که مقدار پارامتر comment در شکل ۵.۱ به صورت “What a cute baby!” برگردانده میشد، نه “What+a+cute+baby%21”.
در هر دو مورد، نهانسازی اطلاعات منجر به APIهای سادهتر برای کدهایی شد که از ماژول HTTP استفاده میکردند.
اما اکثر دانشجویان رابطی برای بازگرداندن پارامترها طراحی کرده بودند که بیش از حد سطحی بود و این باعث از بین رفتن فرصتهایی برای نهانسازی اطلاعات شد.
اکثر پروژهها از یک شیء از نوع HTTPRequest برای نگهداری درخواست تجزیهشده استفاده میکردند و کلاس HTTPRequest متدی شبیه نمونهی زیر برای بازگرداندن پارامترها داشت:
public Map<String, String> getParams() {
return this.params;
}بهجای بازگرداندن یک پارامتر خاص، این متد یک ارجاع به Map داخلی که برای ذخیرهسازی پارامترها استفاده میشود را بازمیگرداند. این متد سطحی است و نمایش داخلی استفادهشده در کلاس را افشا میکند.
هر تغییری در ساختار دادهی داخلی باعث تغییر رابط و نیاز به اصلاح در همهی فراخوانها میشود.
در عمل، تغییرات در پیادهسازی معمولاً شامل تغییرات در نمایش ساختارهای کلیدی داده هستند (مثلاً برای بهبود کارایی). بنابراین، باید تا حد امکان از افشای ساختارهای داخلی اجتناب کرد.
این رویکرد همچنین کار بیشتری را بر عهدهی فراخوان میگذارد: فراخواننده باید ابتدا getParams() را صدا بزند و سپس متد دیگری را روی آن Map فراخوانی کند تا پارامتر خاصی را استخراج کند. همچنین، فراخواننده باید بداند که نباید Map بازگشتی را تغییر دهد، چون این کار وضعیت داخلی کلاس HTTPRequest را تغییر خواهد داد.
در اینجا یک رابط بهتر برای دریافت مقادیر پارامترها آورده شده است:
public String getParameter(String name) { ... }
public int getIntParameter(String name) { ... }متد getParameter مقدار یک پارامتر را به صورت رشته بازمیگرداند. این متد رابطی عمیقتر از getParams فراهم میکند؛ و مهمتر از آن، نمایش داخلی پارامترها را پنهان میکند.
متد getIntParameter مقدار پارامتر را از رشته به عدد صحیح تبدیل میکند (برای مثال، پارامتر photo_id در شکل ۵.۱). این کار نیاز به تبدیل جداگانه توسط فراخواننده را حذف کرده و آن مکانیزم را نیز پنهان میسازد.
در صورت نیاز، میتوان متدهای بیشتری برای انواع دیگر داده (مانند getDoubleParameter) تعریف کرد.
(همهی این متدها در صورتی که پارامتر خواستهشده وجود نداشته باشد یا نتواند به نوع مورد نظر تبدیل شود، استثناء پرتاب میکنند؛ برای سادهسازی، اعلان استثناءها در کد بالا حذف شده است.)
۵.۷ مثال: مقادیر پیشفرض در پاسخهای HTTP
پروژههای HTTP همچنین باید از تولید پاسخهای HTTP نیز پشتیبانی میکردند. رایجترین اشتباه دانشجویان در این زمینه، تعریف نکردن مقادیر پیشفرض مناسب بود.
هر پاسخ HTTP باید نسخهای از پروتکل HTTP را مشخص کند؛ یک تیم از دانشجویان، فراخواننده را مجبور کرده بود که این نسخه را هنگام ایجاد شیء پاسخ، بهصورت صریح مشخص کند. اما نسخهی پاسخ باید با نسخهی درخواست مطابقت داشته باشد، و از آنجا که شیء درخواست هنگام ارسال پاسخ باید بهعنوان آرگومان ارسال شود (زیرا مشخص میکند پاسخ به کجا فرستاده شود)، منطقیتر است که کلاسهای HTTP این نسخه را بهطور خودکار تعیین کنند.
فراخواننده بهاحتمال زیاد نمیداند چه نسخهای را باید مشخص کند، و اگر هم نسخهای را مشخص کند، احتمالاً باعث نشت اطلاعات بین کتابخانهی HTTP و کد فراخوان میشود.
پاسخهای HTTP همچنین شامل هدر Date هستند که زمان ارسال پاسخ را مشخص میکند؛ کتابخانهی HTTP باید برای این مورد نیز مقدار پیشفرض معقولی ارائه دهد.
مقادیر پیشفرض یک اصل کلیدی را نشان میدهند: رابطها باید طوری طراحی شوند که حالت رایج را تا حد ممکن ساده کنند. این مورد مثالی از نهانسازی جزئی اطلاعات نیز هست: در حالت عادی، فراخواننده نیازی به دانستن وجود مقدار پیشفرض ندارد. در موارد نادر که نیاز به تغییر مقدار پیشفرض وجود دارد، فراخواننده میتواند از متدی خاص برای انجام این کار استفاده کند.
هر جا که ممکن بود، کلاسها باید بدون نیاز به درخواست صریح از سوی کاربر، «کار درست» را انجام دهند. مقادیر پیشفرض نمونهای از این رفتار هستند.
مثال منفی آن را میتوان در مثال I/O جاوا (در صفحه ۲۶) مشاهده کرد. بافر کردن در عملیات فایلخوانی آنقدر مطلوب و رایج است که نباید نیاز باشد بهصورت صریح از آن درخواست شود، یا حتی کاربر از وجود آن آگاه باشد؛ کلاسهای I/O باید بهطور پیشفرض آن را ارائه دهند. بهترین قابلیتها آنهایی هستند که کار میکنند بدون آنکه کاربر حتی بداند وجود دارند.
پرچم قرمز: افشای بیش از حد (Overexposure)
اگر یک API برای یک قابلیت رایج، کاربران را مجبور کند دربارهی قابلیتهایی که بهندرت استفاده میشوند نیز اطلاعات کسب کنند، این باعث افزایش بار شناختی برای کاربرانی میشود که به آن قابلیتهای نادر نیازی ندارند.
۵.۸ نهانسازی اطلاعات درون یک کلاس
مثالهای این فصل بر نهانسازی اطلاعات در رابطه با APIهای قابل مشاهده از بیرون تمرکز داشتند، اما نهانسازی اطلاعات در سطوح دیگر سیستم، مانند درون خود کلاس نیز قابل اعمال است.
سعی کنید متدهای خصوصی در یک کلاس را طوری طراحی کنید که هر متد بخشی از اطلاعات یا یک قابلیت خاص را کپسوله کند و آن را از بقیهی کلاس پنهان نماید.
علاوه بر این، سعی کنید تعداد نقاطی که هر متغیر نمونه استفاده میشود را به حداقل برسانید. بعضی از متغیرها ممکن است نیاز باشد در سراسر کلاس در دسترس باشند، اما برخی دیگر فقط در چند نقطه مورد استفاده قرار میگیرند؛ اگر بتوانید تعداد مکانهای استفاده از یک متغیر را کاهش دهید، وابستگیها درون کلاس کاهش یافته و پیچیدگی آن کمتر میشود.
۵.۹ زیادهروی در نهانسازی اطلاعات
نهانسازی اطلاعات فقط زمانی معنا دارد که آن اطلاعات در خارج از ماژول نیازی نباشد. اگر اطلاعاتی در خارج از ماژول مورد نیاز است، نباید آن را پنهان کرد.
فرض کنید عملکرد یک ماژول به برخی پارامترهای پیکربندی وابسته است و استفادههای مختلف از آن ماژول به تنظیمات متفاوتی نیاز دارند. در این حالت، مهم است که پارامترها از طریق رابط ماژول قابل دسترسی باشند تا بتوان آنها را بهدرستی تنظیم کرد.
هدف شما بهعنوان یک طراح نرمافزار باید این باشد که مقدار اطلاعات مورد نیاز خارج از یک ماژول را به حداقل برسانید؛ برای مثال، اگر یک ماژول بتواند بهطور خودکار پیکربندی خود را تنظیم کند، این بهتر از آن است که پارامترهای پیکربندی را آشکار کند.
اما باید بتوانید تشخیص دهید که کدام اطلاعات واقعاً در خارج از ماژول مورد نیاز هستند، و اطمینان حاصل کنید که در این موارد، آن اطلاعات واقعاً در دسترس قرار دارند.
۵.۱۰ نتیجهگیری
نهانسازی اطلاعات و ماژولهای عمیق، ارتباط تنگاتنگی با هم دارند. اگر یک ماژول اطلاعات زیادی را پنهان کند، معمولاً عملکرد بیشتری ارائه میدهد و در عین حال رابط سادهتری دارد. این باعث میشود ماژول عمیقتر شود.
برعکس، اگر یک ماژول اطلاعات زیادی را پنهان نکند، یا عملکرد کمی دارد، یا رابط آن پیچیده است؛ در هر دو صورت، ماژول کمعمق (shallow) خواهد بود.
هنگام تجزیهی یک سیستم به ماژولها، سعی نکنید تحت تأثیر ترتیب اجرای عملیات در زمان اجرا قرار بگیرید؛ این منجر به تجزیهی زمانی خواهد شد، که در نهایت منجر به نشت اطلاعات و ماژولهای کمعمق میشود.
در عوض، دربارهی دانشهای مختلفی که برای انجام وظایف اپلیکیشن لازم است فکر کنید، و هر ماژول را طوری طراحی کنید که یک یا چند قطعه از آن دانش را در خود کپسوله کند. این کار باعث ایجاد طراحیای ساده و تمیز با ماژولهای عمیق خواهد شد.
یادداشت:
دیوید پارناس، «درباره معیارهایی برای تجزیهی سیستمها به ماژولها»، Communications of the ACM، دسامبر ۱۹۷۲.