تصور کن…
تو یک محلهای زندگی میکنی و تازه یه نفر به اون محله اومده. حالا میخوای حدس بزنی اون شخص جدید به کدوم دسته از مردم محله تعلق داره — مثلاً:
آیا اون ورزشکاره؟
یا کتابخونه؟
یا شاید هنرمنده؟
تو نمیدونی اون چیه، اما میتونی یه کار ساده بکنی:
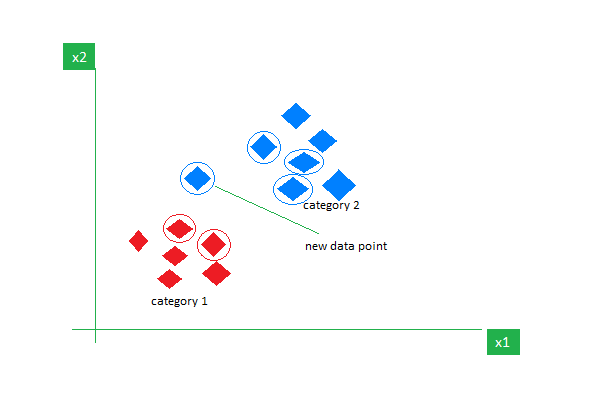
قدم اول: دور و بریهاش رو نگاه کن
میری نگاه میکنی که نزدیکترین همسایههای اون آدم چه کسانی هستن.
مثلاً نگاه میکنی ببینی ۵ نفر از نزدیکترین آدمهای اطرافش چیکارن.
قدم دوم: رأیگیری ساده
فرض کن اون ۵ نفر اینطورین:
۳ نفر ورزشکار
۱ نفر کتابخون
۱ نفر هنرمند
خب، چون بیشترِ همسایههاش ورزشکارن، تو هم حدس میزنی اون آدم جدید هم ورزشکاره.
این همون ایدهی KNN هست.
پس KNN چطوری کار میکنه؟
K رو انتخاب میکنی (مثلاً K=3 یعنی 3 تا همسایه نزدیک).
فاصلهها رو اندازه میگیری بین دادهی جدید و بقیهی دادهها (مثلاً با استفاده از فاصله اقلیدسی — مثل خطکش کشیدن بین نقاط).
K تا نزدیکترین همسایه رو پیدا میکنی.
با رأیگیری میفهمی که اکثریت همسایهها چی هستن.
همون دسته رو برای دادهی جدید انتخاب میکنی.
مثال عددی ساده:
فرض کن ما دادههایی داریم دربارهی میوهها، و میخوایم بفهمیم یک میوه جدید سیب هست یا پرتقال. اطلاعات ما مثلاً شامل وزن و رنگ میوههاست.
میریم تو دیتاست، نزدیکترین 3 میوه مشابه رو پیدا میکنیم. اگه 2 تا از اونا پرتقال باشن، و 1یش سیب، میگیم: پس احتمالاً میوه جدید پرتقاله.
چند نکته مهم
انتخاب مقدار K خیلی مهمه. K خیلی کم یا خیلی زیاد باشه، مدل درست کار نمیکنه.
KNN یه مدل ساده اما قوی هست، ولی اگه دادهها خیلی زیاد باشن یا بُعد زیاد داشته باشن، ممکنه کند بشه.
بهش میگیم مدل non-parametric، چون هیچ فرضی دربارهی شکل دادهها نمیزنه.